こんにちは、本日は音声ファイルから文字起こししたテキストファイルを要約してみます。
実行順序の最後の部分になります。
実行順序
1.動画ファイルから音声データを抽出する。
2.音声データを適当な大きさのファイルに分割する。
3.分割したファイル各々に対して、AIを使って文字起こしを実施する。
4.文字起こししたファイルたちをAIを用いて要約し、議事メモのサマリを作成する。
application_service.pyの中では以下の部分です。
import asyncio
from audio_extractor import AudioExtractor
from audio_splitter import AudioSplitter
from summarizer_factory import SummarizerFactory
from speech_to_text import Transcriber
class MeetingMinutesCreationService():
# 対象動画ファイル指定
target_file = "./data/画面収録 2024-02-28 9.05.31.mov"
async def execute(self):
# 音声ファイル抽出
audio_extractor = AudioExtractor(self.target_file)
audio_file_name = audio_extractor.extract_audio()
# 音声ファイルの分割
splitter = AudioSplitter()
separated_files: list[str] = splitter.split_wav(audio_file_name)
# 音声→文字変換
transcriber = Transcriber()
transcribed_files = await transcriber.perform_transcription(separated_files)
# 文字列の要約
summarizer = SummarizerFactory.get_instance().create_summarizer_instance()
summarizer.summarize_text(transcribed_files)
1. 準備
今回はOpenAIのAPIを用います。
ChatGPTはWeb画面でOpenAI製のLLM(Large Language Model、大規模言語モデル)とやりとりしますが、APIも用意されています。ChatGPTはアカウント登録すれば無料で使用できますが、APIはトークンに応じた料金がかかります。
まずは、APIキーの発行が必要です。ざっくりいうと、
- アカウント登録 (ChatGPTのアカウントがあれば改めて実施する必要はない)
- APIキーを生成する
- クレジットカード登録する
となります。詳細は以下のサイトを参照ください。
https://ai-workstyle.com/gpt-apikey/
2. 実装
今回は以下のライブラリを用います。
ibm-watson
moviepy
python-dotenv
scipy
openai==1.13.3
langchain==0.1.10
langchain-openaipip install -r requirements.txtLangchainはLLMを使用したアプリケーション開発のためのオープンソース・オーケストレーション・フレームワークです。PythonとJavascriptがサポートされています。LLMを使ったアプリケーションを開発する上でのデファクトスタンダードとなっています。
今回もLangchainを利用します。
1.テキスト要約の処理方式
APIには文字数制限がある関係上、長文を一気に要約させることはできません。
その対策として以下の対策があります。(詳細はこちら)
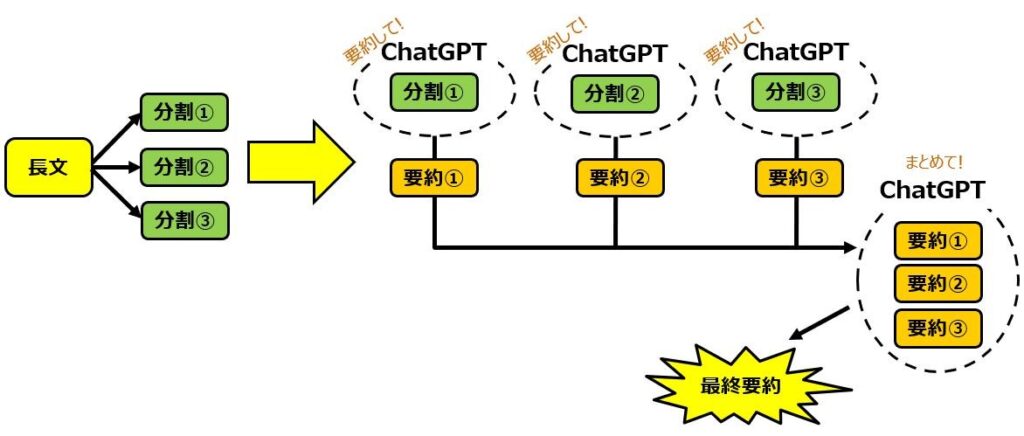
1) Map-Reduce
Map-Reduceの手順は
1)長い文章をいくつかの文章に分割
2)それぞれの文章を要約
3)要約した文章を結合
4)結合した文章をさらに要約
するようなものです。いわゆるHadoopのMap-Reduceの考え方を踏襲したようなものとなります。
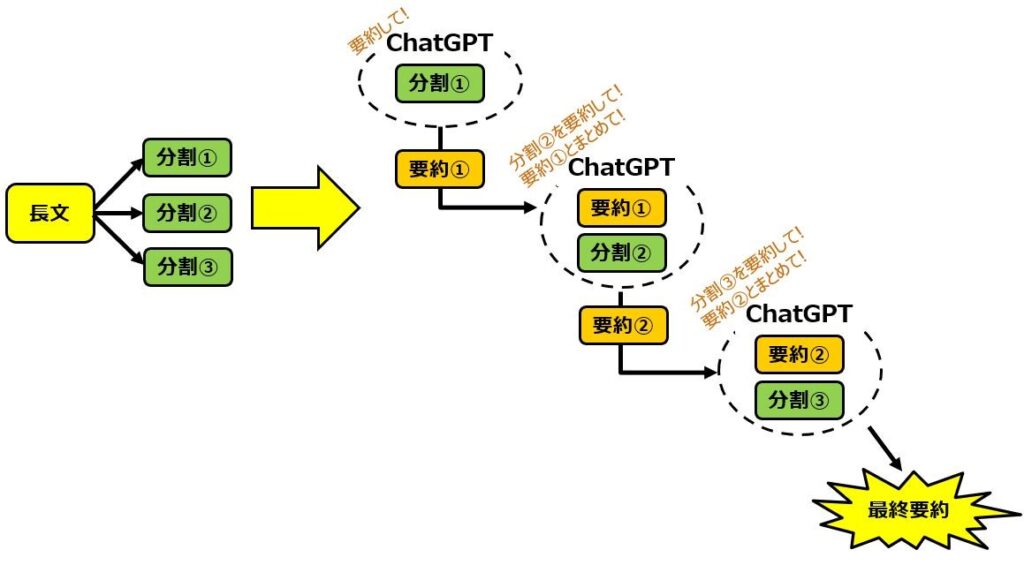
2) Refine
Refineの手順としては
1)長い文章をいくつかの文章に分割
2)分割した文章たちの最初の文章を要約
3)分割した文章たちの次の文章と2)の要約をまとめて要約
4)3)を最後の繰り返し
というような形で、逐次的に要約していく形です。
今回はポピュラーなMap-Reduce方式を採用しました。
2.実装
ということでコードです。まずはsummarizer_factory.pyからです。
from enum import Enum
from typing import Dict
from summarizer import AbstractTextSummarizer
from text_summarizer_openai import OpenAITextSummarizer
from text_summarizer_watson import WatsonxTextSummarizer
from env_settings import EnvSettings
class LLMType(Enum):
OPEN_AI='OPEN_AI'
WATSONX_AI='WATSONX_AI'
class SummarizerFactory():
__instance = None
__env_settings = EnvSettings()
__instance_dict: Dict[LLMType, AbstractTextSummarizer] = {
LLMType.OPEN_AI: OpenAITextSummarizer(),
LLMType.WATSONX_AI: WatsonxTextSummarizer(),
}
@classmethod
def get_instance(cls):
if not cls.__instance:
cls.__instance = cls.__new__(cls)
return cls.__instance
def __init__(self) -> None:
raise NotImplementedError('Cannot Generate Instance By Constructor Because This Class Is Singleton.')
def create_summarizer_instance(self) -> AbstractTextSummarizer:
llm_type = self.__env_settings.get_value_of("LLM_TYPE")
return self.__instance_dict[LLMType[llm_type]]なぜファクトリクラスがあるかですが、文書要約で使用するLLMをスイッチさせたいためとなります。今回はOpenAIのみですが、IBM WatsonXやGoogle Geminiなども使って比較するつもりのためです。Geminiは去年12月にリリースされたマルチモーダル対応ということで個人的に興味深いです。
さて早速テキスト要約のコードは以下になります。
from abc import ABCMeta, abstractmethod
import datetime
from env_settings import EnvSettings
class AbstractTextSummarizer(metaclass = ABCMeta):
api_key: str
env_settings = EnvSettings()
output_path = f"./data/summary_result_{datetime.datetime.now().strftime('%y%m%d%H%M%S')}.txt"
map_prompt_template = """以下の文章を要約して下さい。
------
{text}
------
"""
map_combine_template="""以下の文章を議事メモにまとめてください。決定事項、アクションアイテム、会議録の要約などです。
------
{text}
------
"""
@abstractmethod
def __init__(self) -> None:
pass
@abstractmethod
def summarize_text(self, target_files: list[str]) -> None:
passfrom langchain_openai import ChatOpenAI
from langchain.prompts import PromptTemplate
from langchain.chains.summarize import load_summarize_chain
from langchain.docstore.document import Document
from summarizer import AbstractTextSummarizer
class OpenAITextSummarizer(AbstractTextSummarizer):
def __init__(self) -> None:
self.api_key = self.env_settings.get_value_of('OPEN_AI_API_KEY') # open ai API KEY
def summarize_text(self, target_files):
if not target_files:
return ""
# プロンプトの定義
map_first_prompt = PromptTemplate(template=self.map_prompt_template, input_variables=["text"])
map_combine_prompt = PromptTemplate(template=self.map_combine_template, input_variables=["text"])
# Map-Reduce方式
map_chain = load_summarize_chain(
llm=ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo", api_key=self.api_key),
reduce_llm=ChatOpenAI(temperature=0, model_name="gpt-4", api_key=self.api_key),
collapse_llm=ChatOpenAI(temperature=0, model_name="gpt-4", api_key=self.api_key),
chain_type="map_reduce",
map_prompt=map_first_prompt,
combine_prompt=map_combine_prompt,
collapse_prompt=map_combine_prompt,
token_max=5000,
verbose=True
)
# API実行
docs =[]
for target_file in target_files:
with open(target_file, "r") as file_obj:
docs.append(Document(page_content=file_obj.read()))
result = map_chain({"input_documents": docs}, return_only_outputs=True)
# ファイル出力
with open(self.output_path, "w") as file_obj:
file_obj.write(result["output_text"])コードの通りなので、あまり補足することもないのですが、、
どのLLMを使用するにしても、共通的な処理はあるかと思われるので、そういったものをsummarizer.pyに集めています。(現時点ではあまりないですが。。)
load_summarize_chainがLLMとやりとりする関数であり、Map-reduce/refineなどの処理方式の選択もload_summarize_chainの引数で指定可能となっています。
3. まとめ
今回は長い文章を要約するコードを書いてみました。今回はopenAIのみですが、そのうちいろいろなLLMにリクエストを投げてどんなレスポンスになるか比較してみたいと思います。
最後まで読んでいただきありがとうございます。
質問等はコメント欄かお問合せにてよろしくおねがいいたします。